
Hadoop複数構成インストール手順
Hadoopの複数構成の構築手順を説明する。
目次
Hadoopインストール手順
1.はじめに
目的
Hadoopの動作確認環境の構築する。
すでにCentOSが稼働しているサーバー2台があるものとして、ソフトウェアのインストール等を行う。
サーバーは、マスターとスレイブの2台構成とし、使用時はリモート接続できるようにする。
2.構築環境について
前提
使用OS
◎ CentOS7.0 (64bit)
インストールするソフトウェア
◎ jdk1.8.0
◎ Hadoop
◎ wget
◎ telnet(サーバー&クライアント)
◎ openssh
サーバー設定
今回は2台構成とし、下記の設定を行うものとする。
| ホスト名 | Libra1 | Libra2 |
| IPアドレス | 192.168.3.40 | 192.168.3.41 |
| 役割 | master | slave |
| HDFSポート | 50010 | 50020 |
3.準備
ユーザー追加
ユーザー登録
Hadoopで利用するユーザーを登録する。
# useradd hdpuserパスワード設定
パスワードを設定する。
# passwd hdpuser確認用を含めて2度、任意のパスワードを入力する。
※簡単なパスワードの場合「警告」が表示されるが、そのまま設定する。
Changing password for hdpuser
New password: ※1回目の入力
Retype new password: ※2回目の入力ユーザー変更
ユーザーを変更する。
# su hdpuser場所確認
ホームディレクトリに移動し、場所を確認する。
# cd $HOME
# pwd場所の表示例)
/home/hdpuserフォルダ追加
Hadoopで利用するフォルダを追加する。
# mkdir tempJDKのインストール
OpenJDKインストール
OpenJDKをインストールする。
# yum -y install java-1.8.0-openjdk-devel※終了までの時間が長めです。
インストール先確認
Javaコマンドのパスをたどって、Javaのインストール先を確認する。
# which java
/bin/java
# readlink /bin/java
/etc/alternatives/java
# readlink /etc/alternatives/java
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-0.b14.el7_4.x86_64/jre/bin/java※インストールしたJDK「java-1.8.0-openjdk-1.8.0.161-0.b14.el7_4.x86_64」が確認できるまで、コマンドでたどる。(readlinkコマンドを繰り返す。)
JAVA_HOME設定
ログイン時に自動的に設定されるように、.bashrcにJAVA_HOMEのエクスポートコマンドを追記する。
対象のフォルダは、上記で確認したパスを設定する。
# echo “export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-0.b14.el7_4.x86_64” >> ~/.bashrc再ログイン
bashrcに、JAVA_HOMEのエクスポート設定を行っているので、一度ログアウトしてログインし直す。
JAVA_HOME確認
ログイン後に、JAVA_HOMEを出力し表示内容を確認する。
# echo $JAVA_HOME出力例)
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-0.b14.el7_4.x86_64※.bashrcに追記したとおりにパスが設定されていることを確認する。
4.Hadoop環境の構築
インストール
Apach Hadoopを取得するためのアドレスを事前に確認すること。
◎ apache
ダウンロードをクリック
ダウンロードをクリックする。
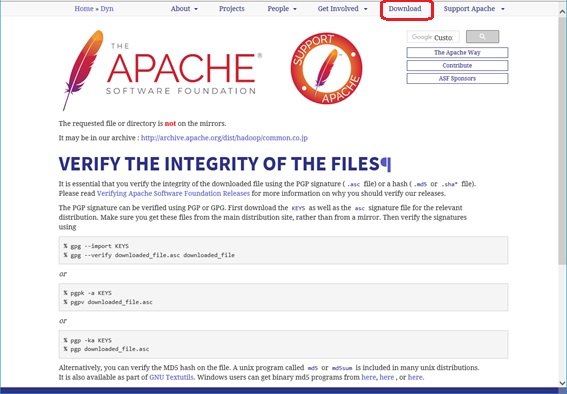
ダウンロード先選択
HTTPの項目からダウンロード先を選択する。
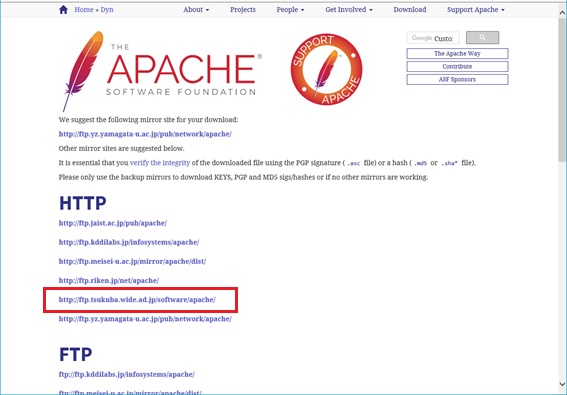
必要なファイル選択
ダウロード先を選択すると、フォルダ選択に切り替わるので、Hadoopフォルダから必要なファイルを選択する。

※スクロールさせて、Hadoopフォルダを探す。
選択例)
http://ftp.tsukuba.wide.ad.jp/software/apache/hadoop/common/hadoop-3.0.1/hadoop-3.0.1.tar.gz
Hadoopダウンロード
上記で選択したURLからHadoopをダウンロードする。
# wget -p http://ftp.tsukuba.wide.ad.jp/software/apache/hadoop/common/hadoop-3.0.1/hadoop-3.0.1.tar.gz※処理が終了するのに、時間がかかります。
ダウンロードファイル確認
上記ダウンロードで選択したファイルを同じタイムスタンプのファイルが取得できるので確認する。
# pwd
/home/hdpuser
# ls –l結果例)
-rw-rw-r-- 1 hdpuser hdpuser 307606299 3月 24 03:30 hadoop-3.0.1.tar.gzダウンロードファイルを展開
ダウンロードしたファイルを展開する。
# tar -xzvf hadoop-3.0.1.tar.gz※ファイルがすべて解凍されるまで時間がかかります。
ライブラリ移動
展開されたライブラリの移動先→/usr/local
# mv hadoop-3.0.1 /usr/local/移動確認
移動できたことを確認する。
# ls -l /usr/local/hadoop-3.0.1出力例)
合計 188
-rw-rw-r-- 1 hdpuser hdpuser 147066 2月 8 07:17 LICENSE.txt
-rw-rw-r-- 1 hdpuser hdpuser 20891 1月 24 11:07 NOTICE.txt
-rw-rw-r-- 1 hdpuser hdpuser 1366 8月 30 2017 README.txt
drwxr-xr-x 2 hdpuser hdpuser 4096 3月 17 08:24 bin
drwxr-xr-x 3 hdpuser hdpuser 19 3月 17 08:02 etc
drwxr-xr-x 2 hdpuser hdpuser 101 3月 17 08:24 include
drwxr-xr-x 3 hdpuser hdpuser 19 3月 17 08:24 lib
drwxr-xr-x 4 hdpuser hdpuser 4096 3月 17 08:24 libexec
drwxrwxr-x 3 hdpuser hdpuser 4096 4月 1 22:07 logs
drwxr-xr-x 3 hdpuser hdpuser 4096 3月 17 08:02 sbin
drwxr-xr-x 4 hdpuser hdpuser 29 3月 17 08:39 share環境変数設定
「.bashrc」に環境変数を設定する。
# vi /home/hdpuser/.bashrc追記例)
export HADOOP_HOME=/usr/local/hadoop-3.0.1
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH※Hadoopの設定が存在しない環境を設定しているので、最後尾に上記内容をすべて追記する。
再ログイン
「.bashrc」に、エクスポート設定を行ったので、JAVA_HOMEのとき同様、一度ログアウトしてログインし直す。
インストールの終了確認
Hadoopのバージョンを確認し、インストールの終了を確認する。
# hadoop version出力例)
Hadoop 3.0.1
Source code repository Unknown -r 496dc57cc2e4f4da117f7a8e3840aaeac0c1d2d0
Compiled by lei on 2018-03-16T23:00Z
Compiled with protoc 2.5.0
From source with checksum 504d49cc3bcf4e2b56e2fd44ced8572
This command was run using /usr/local/hadoop-3.0.1/share/hadoop/common/hadoop-common-3.0.1.jar※設定前は、Hadoopがインストールされていないので、上記コマンドは実行できなかったので、コマンドが実行されて、インストールしたHadoopのversionを確認できればよい。
初期設定
Hadoopの設定ファイル(xml)にプロパティ情報を追加
設定ファイルの存在を確認するためフォルダの内容を出力する。
# ls-l $HADOOP_HOME/etc/hadoop出力例)
合計 172
-rw-r--r-- 1 hdpuser hdpuser 7861 3月 17 08:13 capacity-scheduler.xml
-rw-r--r-- 1 hdpuser hdpuser 1335 3月 17 08:16 configuration.xsl
-rw-r--r-- 1 hdpuser hdpuser 1211 3月 17 08:13 container-executor.cfg
-rw-r--r-- 1 hdpuser hdpuser 995 4月 1 22:05 core-site.xml
-rw-r--r-- 1 hdpuser hdpuser 3999 3月 17 08:01 hadoop-env.cmd
-rw-r--r-- 1 hdpuser hdpuser 16381 3月 17 08:24 hadoop-env.sh
-rw-r--r-- 1 hdpuser hdpuser 3323 3月 17 08:01 hadoop-metrics2.properties
-rw-r--r-- 1 hdpuser hdpuser 10206 3月 17 08:01 hadoop-policy.xml
-rw-r--r-- 1 hdpuser hdpuser 3414 3月 17 08:01 hadoop-user-functions.sh.example
-rw-r--r-- 1 hdpuser hdpuser 1113 4月 1 21:01 hdfs-site.xml
-rw-r--r-- 1 hdpuser hdpuser 1484 3月 17 08:04 httpfs-env.sh
-rw-r--r-- 1 hdpuser hdpuser 1657 3月 17 08:04 httpfs-log4j.properties
-rw-r--r-- 1 hdpuser hdpuser 21 3月 17 08:04 httpfs-signature.secret
-rw-r--r-- 1 hdpuser hdpuser 620 3月 17 08:04 httpfs-site.xml
-rw-r--r-- 1 hdpuser hdpuser 3518 3月 17 08:02 kms-acls.xml
-rw-r--r-- 1 hdpuser hdpuser 1351 3月 17 08:02 kms-env.sh
-rw-r--r-- 1 hdpuser hdpuser 1747 3月 17 08:02 kms-log4j.properties
-rw-r--r-- 1 hdpuser hdpuser 682 3月 17 08:02 kms-site.xml
-rw-r--r-- 1 hdpuser hdpuser 13238 3月 17 08:01 log4j.properties
-rw-r--r-- 1 hdpuser hdpuser 951 3月 17 08:16 mapred-env.cmd
-rw-r--r-- 1 hdpuser hdpuser 1764 3月 17 08:16 mapred-env.sh
-rw-r--r-- 1 hdpuser hdpuser 4113 3月 17 08:16 mapred-queues.xml.template
-rw-r--r-- 1 hdpuser hdpuser 845 4月 1 21:06 mapred-site.xml
drwxr-xr-x 2 hdpuser hdpuser 23 3月 17 08:01 shellprofile.d
-rw-r--r-- 1 hdpuser hdpuser 2316 3月 17 08:01 ssl-client.xml.example
-rw-r--r-- 1 hdpuser hdpuser 2697 3月 17 08:01 ssl-server.xml.example
-rw-r--r-- 1 hdpuser hdpuser 2642 3月 17 08:04 user_ec_policies.xml.template
-rw-r--r-- 1 hdpuser hdpuser 10 3月 17 08:01 workers
-rw-r--r-- 1 hdpuser hdpuser 2250 3月 17 08:13 yarn-env.cmd
-rw-r--r-- 1 hdpuser hdpuser 5406 3月 17 08:13 yarn-env.sh
-rw-r--r-- 1 hdpuser hdpuser 690 3月 17 08:13 yarn-site.xml①mastersの更新
mastersの更新を行う。
# vi $HADOOP_HOME/etc/hadoop/masters追記例)
libra1※初期時は存在しないので新規作成する。
②slavesの更新
slavesの更新を行う。
# vi $HADOOP_HOME/etc/hadoop/slaves追記例)
libra1
libra2初期時は存在しないので新規作成する。
※3台以上のサーバーで構成する場合は、すべてのホスト名を記載する。
③core-site.xmlの更新
core-site.xmlの更新を行う。
# vi $HADOOP_HOME/etc/hadoop/core-site.xml追記例)
<property>
<name>fs.defaultFS</name>
<value>hdfs://libra1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdpuser/temp</value>
</property>※必ず、<configrration>と、</configration>の間に追記すること。
④hdfs-site.xmlの更新
hdfs-site.xmlの更新を行う。
# vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml追記例)
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.http.address</name>
<value>libra1:50010</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>libra2:50020</value>
</property>※必ず、<configrration>と、</configration>の間に追記すること。
⑤mapred-site.xmlの更新
mapred-site.xmlの更新を行
# vi $HADOOP_HOME/etc/hadoop/maapred-site.xml追記例)
<property>
<name>mapred.job.tracker</name>
<value>libra1:9001</value>
</property>Slaveの作成
設定しているサーバーは、Master用に使うものとする。
一度、サーバー停止させて、この時点のクローンを作成する。
# shutdown –h nowクローン作成手順は、省略する。物理サーバーで構築する場合は、同じ手順を繰り返し行う。
Slave用のサーバーを作成後、「2.環境構築について 2-2.サーバー設定」のように、Masterとは異なるホスト名、IPアドレスなどの設定がすんでいるものとして以降の作業を継続する。
SSHの設定
Master側のサーバーで操作を行う。
①SSH Keyの作成
# ssh-keygen -t dsa※パスフレーズを求められるが、空欄のままEnterを押下する。
②hdpuserで利用するため、authorized_keysとして配置する
# cat .ssh/id_dsa.pub >> .ssh/authorized_keys
# chmod 600 .ssh/authorized_keys5.動作確認
各サーバーへのログイン
MasterとSlaveにそれぞれログインしながら確認をおこなう。
※TeraTarmを2つ起動して、それぞれ接続して進める。
NameNodeのフォーマット
Namenodeをフォーマットする。
# hadoop namenode -formatMasterサーバーのみ操作を行う。
上記コマンドを実行した場合の結果例)
common.Storage: Storage directory /home/hdpuser/temp/dfs/name has been successfully formattedログの最後付近に上記のように成功した内容の出力があることを確認する。
※Slaveサーバーでは実施しない。
起動
起動前の状態確認
# jpsMasterサーバー、Slaveサーバーの両方でそれぞれ操作を行う。
上記コマンドを実行した場合の結果例)
6711 Jps番号は、プロセスが起動した際に割り当てられるので、毎回異なる数字になる。
ここでは、まだjpsしか標示されていない状態であることを確認する。
起動シェルを実行
# start-all.shMasterサーバーのみ操作を行う。
上記コマンドを実行した場合の結果例)
WARNING: Attempting to start all Apache Hadoop daemons as hdpuser in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [libra2]
Starting resourcemanager
Starting nodemanagersmaster側で開始した結果、slaveもスタートしている。
起動後の状態確認
# jps再び、Masterサーバー、Slaveサーバーの両方でそれぞれ操作を行う。
Masterで起動した結果、Master、Slaveそれぞれのサーバーでプロセスが起動したことを確認する。
上記コマンドを実行した場合の結果例)
Masterサーバー側
8646 NameNode
9128 ResourceManager
9594 Jps
8764 DataNode
9421 NodeManagerSlaveサーバー側
3541 SecondaryNameNode
3574 Jps動作の確認
Masterサーバーのみで操作を行う。
入力データ
入力用ファイルを作成する。
# vi test_input.txt以下のような内容で追記する。
追記例)
a b c c d e a b d e e s c a g※Slaveサーバーでは実施しない。
作成したファイルの配置
HDFSにフォルダを作成する。
# hadoop fs -mkdir /inputファイルを配置する。
# hadoop fs -put test_input.txt /input配置状況を確認する。
# hadoop fs -ls -R /上記コマンドを実行した場合の結果例)
drwxr-xr-x - hdpuser supergroup 0 ※作成日時 /input
-rw-r--r-- 3 hdpuser supergroup 31 ※作成日時 /input/test_input.txt※作成日時の部分は、ファイルシステムへ配置した日時が表示される。
サンプルプログラムの実行
# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /input /output実行時、ログの最後に出入力のバイト数が表示されて処理が終了する。
・・・ 途中略 ・・・
File Input Format Counters
Bytes Read=XX ※読み込んだデータサイズ
File Output Format Counters
Bytes Written=YY ※出力したデータサイズ結果確認
処理後の状況を確認する。
$ hadoop fs -ls -R /上記コマンドを実行した場合の結果例)
drwxr-xr-x - hdpuser supergroup 0 ※作成日時 /input
-rw-r--r-- 3 hdpuser supergroup 31 ※作成日時 /input/test_input.txt
drwxr-xr-x - hdpuser supergroup 0 ※出力日時 /output
-rw-r--r-- 3 hdpuser supergroup 0 ※出力日時 /output/_SUCCESS
-rw-r--r-- 3 hdpuser supergroup 33 ※出力日時 /output/part-r-00000※出力日時部分は、実行結果で、ファイルやフォルダが作成された日時
作成されたファイルの内容を確認する。
hadoop fs -cat /output/part-r-00000上記コマンドを実行した場合の結果例)
a 3
aa 1
b 3
c 4
d 3
e 4
g 1
s 1入力ファイル2つの中から出現した単語をカウントしている。
空白で区切って、判別しているため、「a」と「aa」は別々にカウントされている。
終了
停止前の状態確認
$ jpsMasterサーバー、Slaveサーバーの両方でそれぞれ操作を行う。
上記コマンドを実行した場合の結果例)
Masterサーバー
8646 NameNode
9128 ResourceManager
9683 Jps
8764 DataNode
9421 NodeManagerSlaveサーバー
3541 SecondaryNameNode
3574 Jps停止処理
$ stop-all.shMasterサーバーのみ操作を行う。
上記コマンドを実行した場合の結果例)
WARNING: Stopping all Apache Hadoop daemons as hdpuser in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [libra2]
Stopping nodemanagers
Stopping resourcemanagermaster側で開始した結果、セカンダリーのlibra2も停止している。
停止後の状態確認
$ jpsMasterサーバー、Slaveサーバーの両方でそれぞれ操作を行う。
上記コマンドを実行した場合の結果例)
10333 Jpsプロセスが終了したことをそれぞれ確認し、動作確認を終了とする。